Chapter 3 Data
“In God we trust, all others bring data.”
—W. Edwards Deming
3.1 What is data?
At its simplest, data is information. For the purposes of statistical analysis, the majority of data takes the form of numbers that represent things. The number 70 represents my height in inches. It is a data point.
Context is important when it comes to data. If I had given you the number 70 with no other information, it wouldn’t be very useful. It takes on meaning when I tell you what it is meant to represent. Similarly, if I give you the number 22 with no other information, you can’t do much with that. It’s only when I tell you that the number represents my age that it is informative.
Unfortunately, data (for our purposes) doesn’t just materialize out of thin air. We have to collect it. That’s where measurement comes in.
3.2 Types of Data and Measurement
Measurement is the process of quantifying something. By measuring my height, I assigned a number to myself that I can then use. I can share it with friends, compare it with others my age, or feel sad that it’s not a little higher. By the same process, I can measure the heights of 20 other people. I would then be collecting data.
Now, measurement is a hot topic. And really, it’s just a theory. There’s no perfect consensus on the proper way to think about measurement. Sorry to introduce some gray area and subjectivity, but that’s where we’re at. Who said things had to be easy? I won’t bore you with the details (there are too many to cover here anyway), but interested readers can read more about it elsewhere3.
Gray area is difficult to live in when it comes to mathematics, so at a point we must be decisive. One of the most widely accepted models of measurement in the field of psychology was published by Stanley Smith Stevens in 1946. Stevens classified measurement as falling into four types: nominal, ordinal, interval, or ratio. Each has specific characteristics and huge implications for how we handle data.
3.2.1 Nominal
Nominal measurements are those that differ qualitatively from one another. They are typically used for identification and little else. There is a lot of freedom given to nominal measurements and consequently difficulty defining them precisely. It is almost easier to speak of what you cannot do with nominal measurements. You cannot order them in a way such that one is greater than another.
Some examples of nominal measurements include: gender, ethnicity, nationality, and favorite flavor of ice-cream.
3.2.2 Ordinal
Ordinal measurements are those that can be ordered (isn’t it nice when names make sense?). In other words, we can rank things measured on an ordinal scale. We are allowed to say that one thing is less than another thing. Beyond that, there’s not much we can do. This measurement tells us nothing about the distance between each measurement, only the order.
Some examples of ordinal measurements include: letter grades, pain rating scales, personality questionaires, and race placement (1st place, 2nd place, etc.).
3.2.3 Interval
Interval measurements are those that contain, you guess it, intervals! These measurements are such that a 1-unit decrease is equal to a 1-unit increase. Whereas ordinal scales told us nothing about the distance between measurements, interval scales finally allow us to do so. An important thing to note about interval measurements is that they do not have a true zero-point. It doesn’t make sense to speak of “zero temperature.”
Some examples of interval measurements include Fahrenheit and hours on a clock.
3.2.4 Ratio
Ratio measurements give us the most information out of the four types. Ratio scales are nearly identical to interval scales. The big difference is that ratio scales actually have a true zero point!
Some examples of ratio measurements include: Kelvin, distance, age, and weight.
3.3 Distributions
Data is usually distributed among a number of values. This can be examined in a number of ways.
3.3.1 Frequencies Distributions
The frequency, f, of data refers to the amount of times each value occurs in the set. The following table shows the set of frequencies for a data set.
| Grades | f | rf | crf |
|---|---|---|---|
| A | 15 | .20 | 1.0 |
| B | 25 | .34 | .80 |
| C | 20 | .27 | .46 |
| D | 11 | .15 | .19 |
| F | 3 | .04 | .04 |
\(\Large n = sum\ of\ all\ frequencies\)
The letter n tells us the number of scores, participants, or the sum of the frequencies. In this case, n refers to all three and equals 74.
The relative frequencies, rf, can be interpreted as percentages. For example, 20% of the participants recieved an A.
The cumulative relative frequencies, crf, tell us the frequency of that value and all values lower than that value. For example, 46% of the participants recieved at least a C.
3.3.2 Graphical Distributions
A bar graph is a visual representation of the frequencies in a data set when the variable is categorical or discrete.
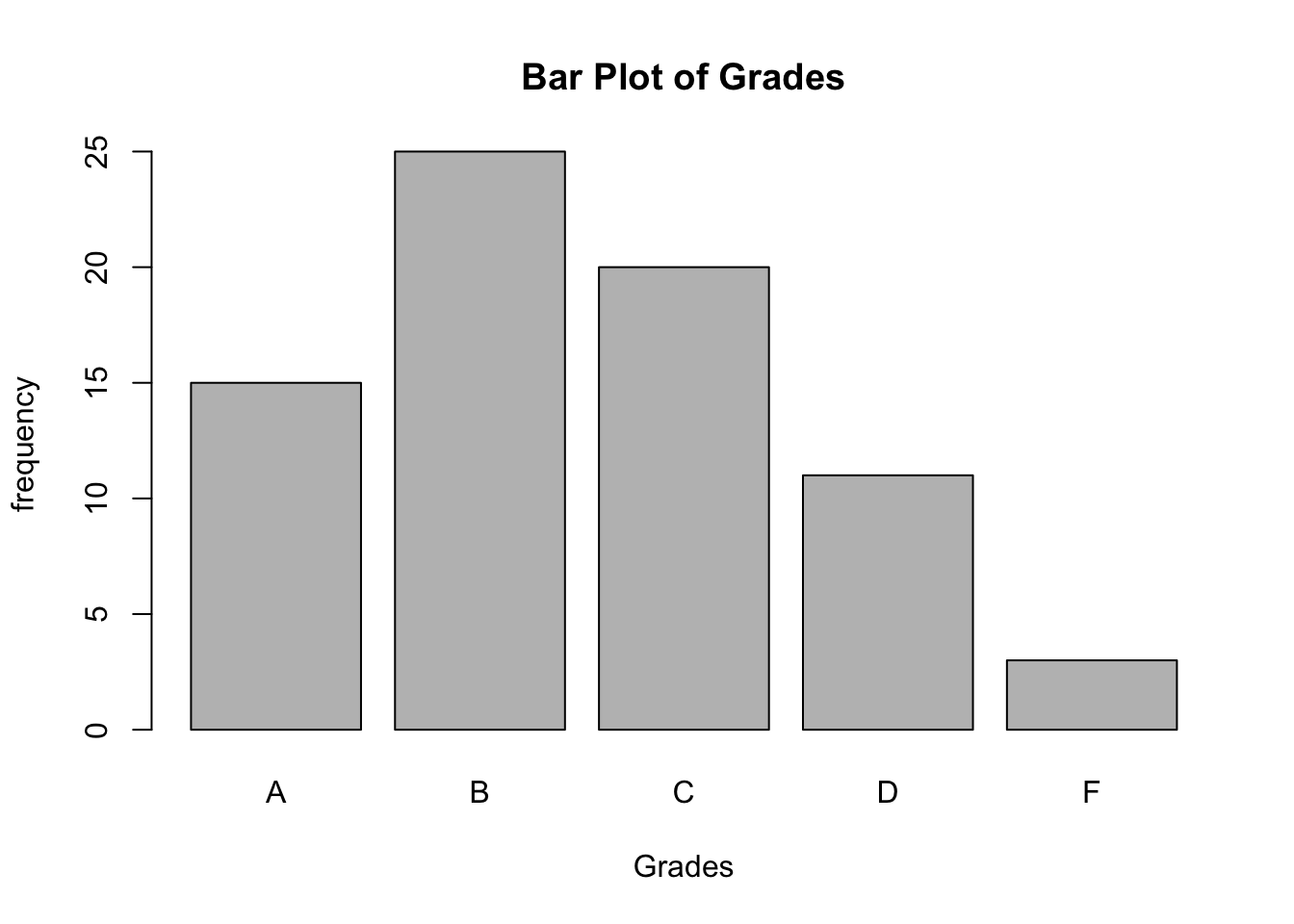
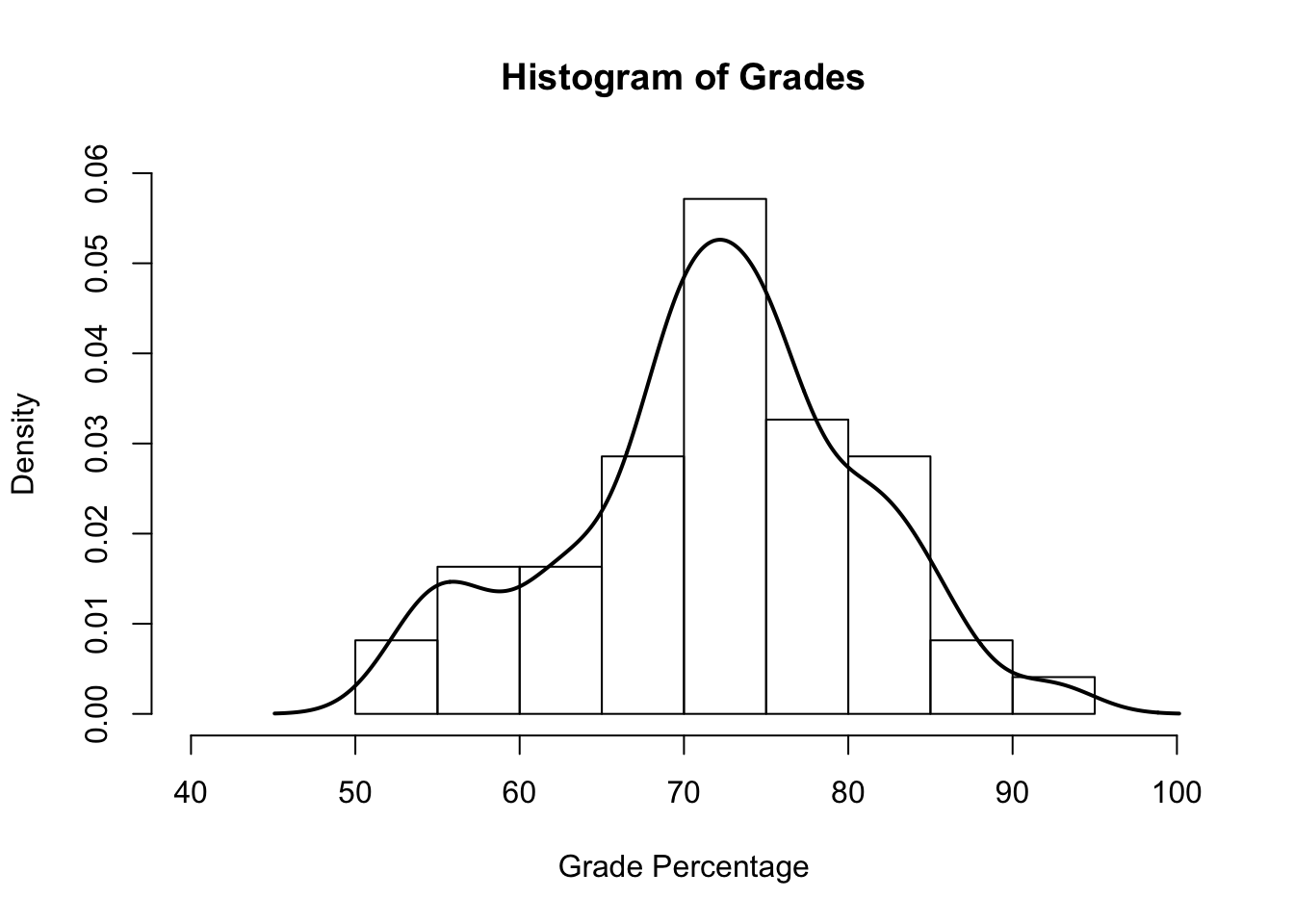
A histogram is a visual representation of the frequencies in a data set when the variable is continuous. Histograms look similar to a bar graph. Notice that instead, the bars on a histogram are touching.
Each of our letter grades in the last example corresponded to an actual percentage. Let’s look at the distribution of those percentages.
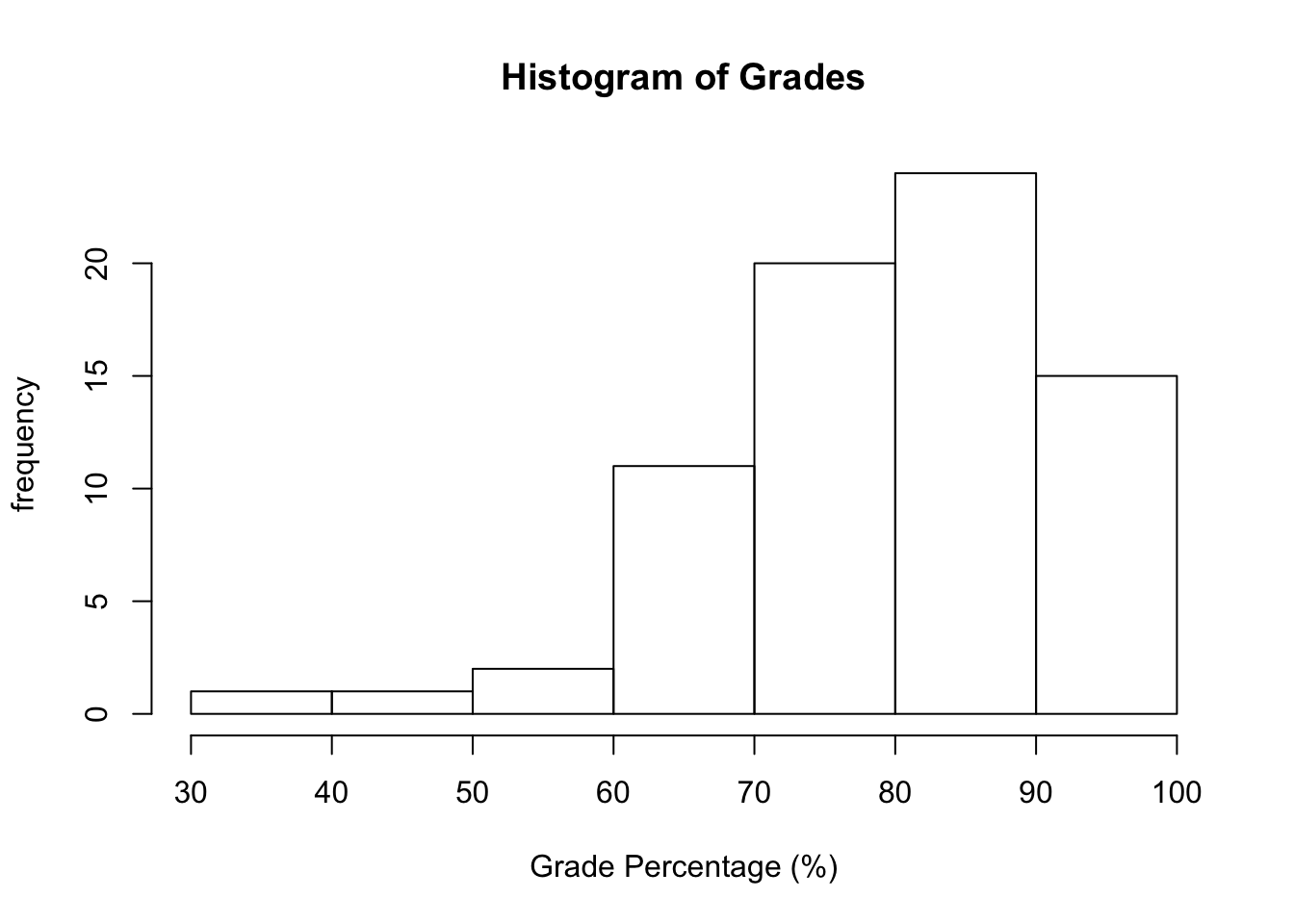
3.3.3 Probability Distributions
Probability distributions show the chances of selecting a value at random from a set. We can plot an approximated line on our histogram to demonstrate a probability distribution. This is called a probability density curve.
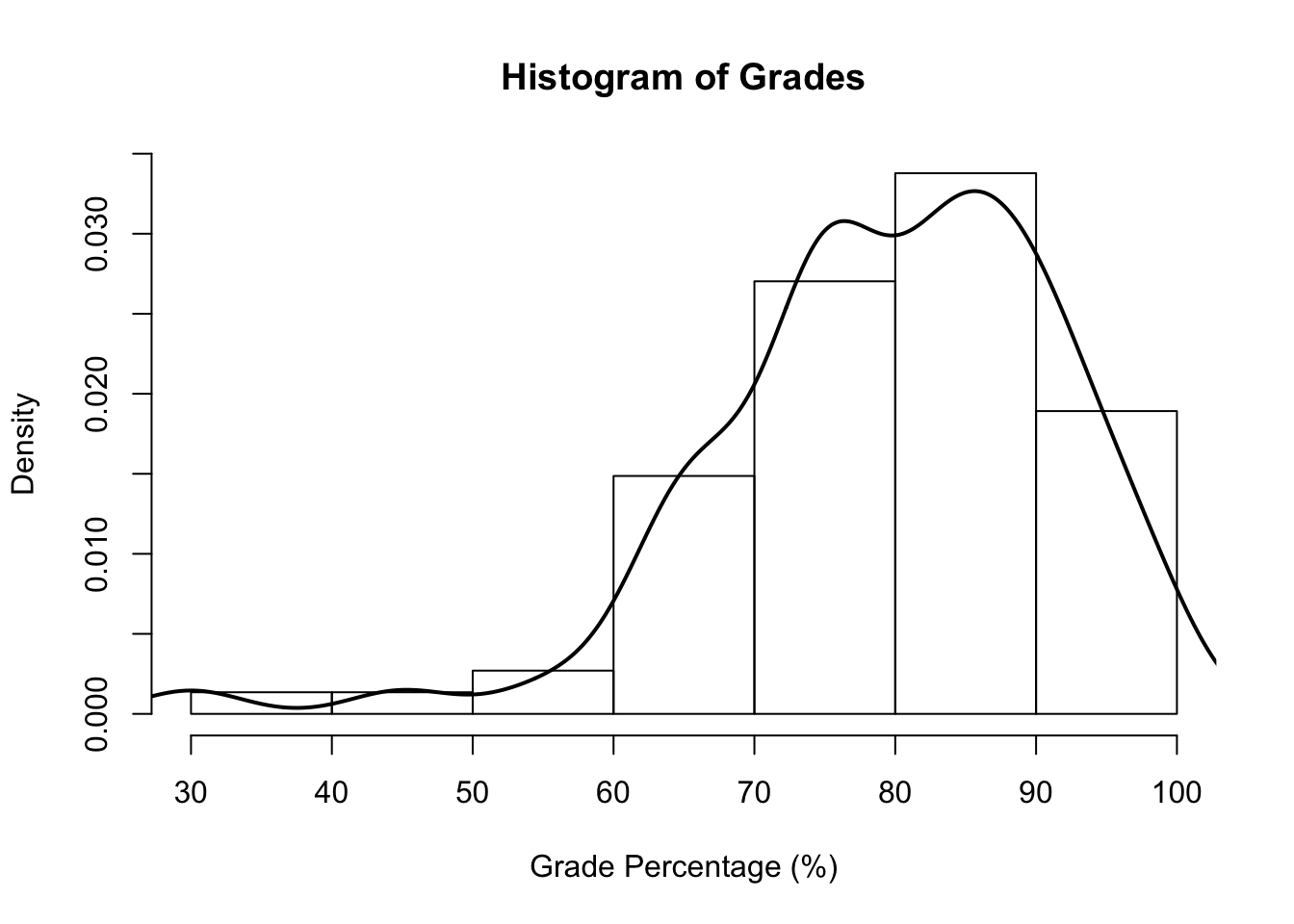
The higher the line, the higher the probability at that value. If we were to select a random grade from this set, this graph suggests that we would likely choose one between \(.70\) and \(1\). The line is a lot lower near \(.30\), suggesting that such a score is unlikely.
Note: If you really wanted to find the exact probability of picking a specific value at random, that probability would actually be quite small. Instead, statisticians often look at the probability of values within intervals.
3.3.4 The Normal Distribution
Distributions of actual data, like in the previous section, are called empirical distributions. We also talk about theoretical distributions, which have certain shapes and properties.
The normal distribution is a theoretical distribution that looks like a bell. For this reason, it is often called a bell curve. Normal distributions have a clump of scores in the middle (near the mean) that dwindle out in tails (moving away from the mean). Here is an example of normally distributed grades:
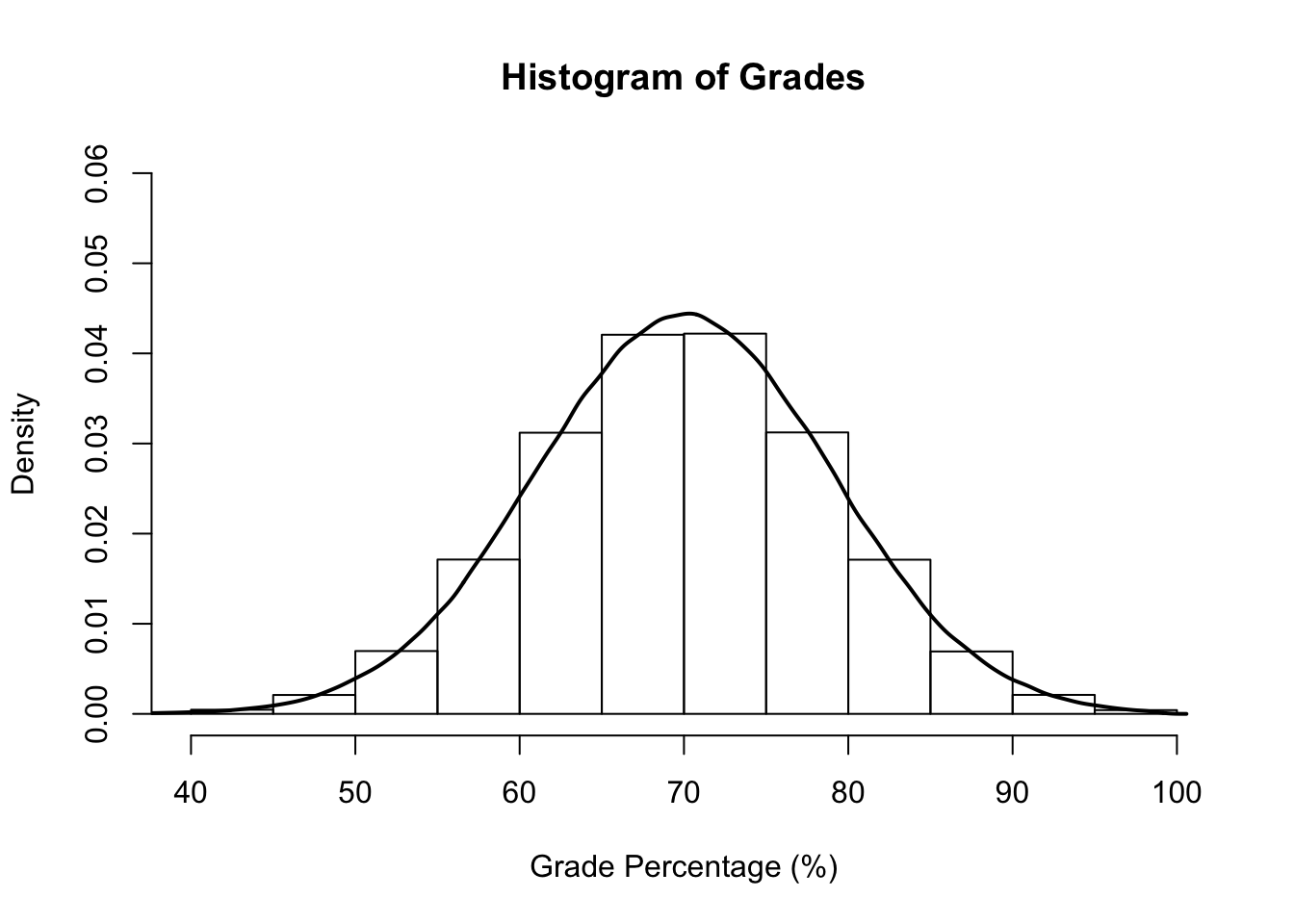
Statisticians will often talk about the central limit theorem, which is a fancy term that basically means: the larger your sample size, the closer it will get to a normal distribution.
The example above is a distribution of \(800,000\) scores. That is a lot. Contrast that with a distribution from only \(50\) scores:
Sure, it’s still somewhat normal, but it’s nowhere near as nice and normal as the previous example.
insert a footnote to direct students↩︎